新浪科技讯 3月10日上午消息,由原华为天才少年稚晖君(彭志辉)创立的智元机器人今日发布,首个通用具身基座大模型GO-1。
据悉,该模型开创性地提出了Vision-Language-Latent-Action (ViLLA) 架构,该架构由VLM(多模态大模型) + MoE(混合专家)组成,其中VLM借助海量互联网图文数据获得通用场景感知和语言理解能力,MoE中的Latent Planner(隐式规划器)借助大量跨本体和人类操作视频数据获得通用的动作理解能力,MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力,三者环环相扣,实现了可以利用人类视频学习,完成小样本快速泛化,降低了具身智能门槛,并成功部署到智元多款机器人本体。(文猛)
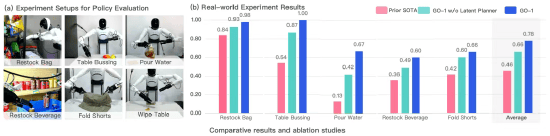
据悉,相比已有的最优模型,GO-1平均成功率提高了32%(46%->78%)。其中,在执行“Pour Water”(倒水)、“Table Bussing”(清理桌面) 和 “Restock Beverage”(补充饮料) 任务表现尤为突出。
(责任编辑:宋政 HN002)
【免责声明】本文仅代表作者本人观点,与和讯网无关。和讯网站对文中陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完整性提供任何明示或暗示的保证。请读者仅作参考,并请自行承担全部责任。邮箱:news_center@staff.hexun.com